تخيل إنك في كافيه، وقاعد بتشرب قهوتك، وفجأة بتسمع الناس حواليك بيحكوا عن ChatGPT وكيف إنه بيقدر يكتب
كود، يلخص مقالات، وحتى يكتب نكت!
قبل كم سنة كانت كل خوارزمية ذكاء اصطناعي محبوسة بصندوقها الخاص (خوارزمية بتفهم صور بس، وثانية بتفهم نصوص
بس).
بس فجأة... ظهر مصطلح قلب الموازين: الـ Foundation Models.
هاي مش مجرد موديلات عادية؛ هاي "موسوعات" ضخمة تدربت على كميات مرعبة من الداتا، وصارت هي الأساس اللي
بنقدر نبني عليه أي تطبيق ذكاء اصطناعي بخطر على بالك، من غير ما نرجع لنقطة الصفر! ✨
رح نشوف كيف هاي النماذج بتشتغل، وكيف غيرت شكل الـ AI للأبد.
🤖 بداية القصة... هل الذكاء الاصطناعي رح يوخذ مكاننا؟
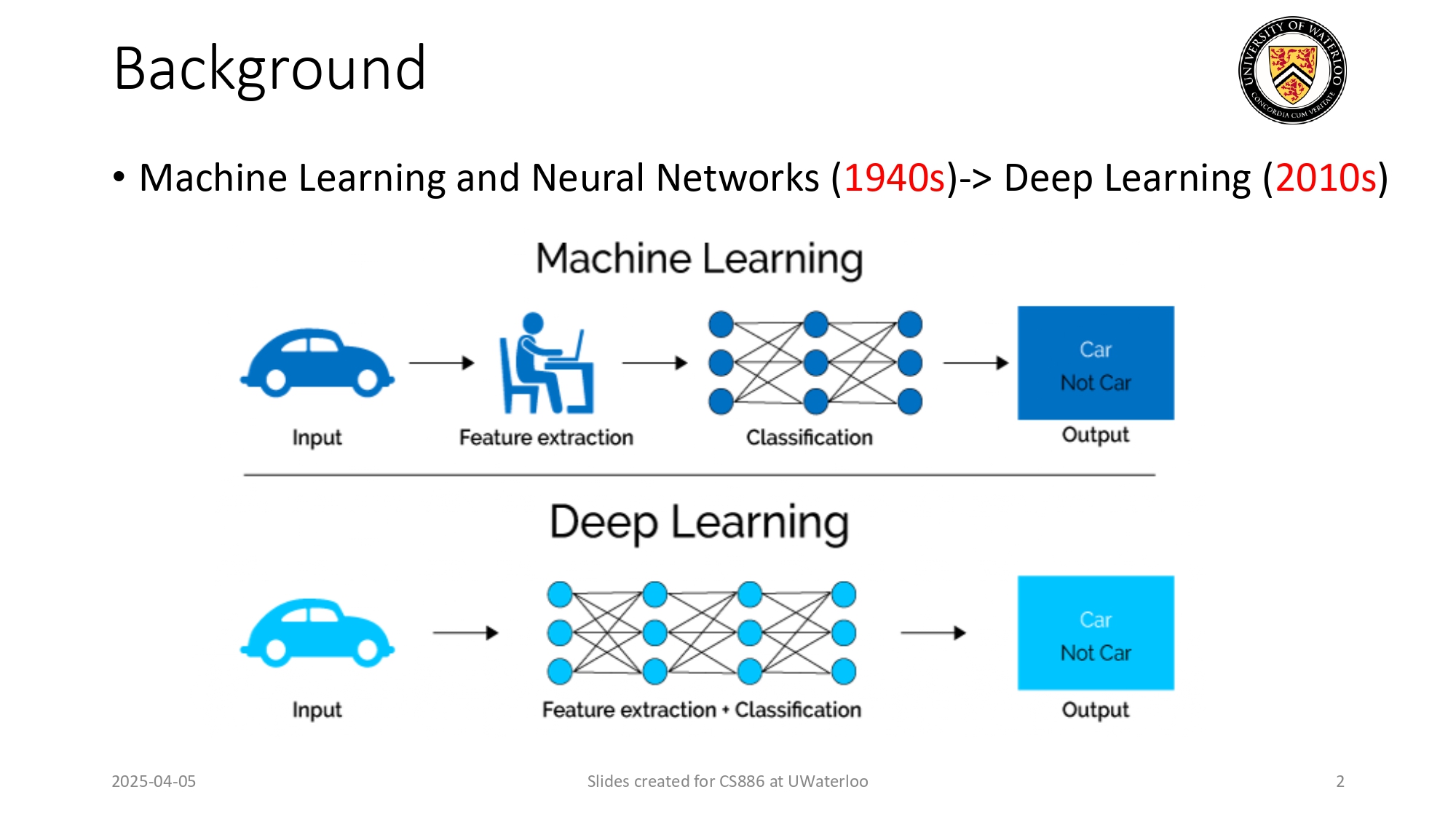
الفرق بين الـ Machine Learning والـ Deep Learning 🧠⚔️
عشان نفهم من وين إجت الـ Foundation Models، لازم نرجع خطوة لورا ونشوف كيف تطور الذكاء الاصطناعي:
Machine Learning (الماضي القريب): تخيل إنك بدك تعلم خوارزمية
كيف تميز شو اللي بالصورة (سيارة ولا مش سيارة). في الـ ML، لازم إنت (كإنسان) تقعد وتحدد "الميزات"
(Feature Extraction) يدوياً. مثلاً، تحكيلها "السيارة إلها عجلات
والباقي لأ". هذا كان بوخذ وقت وجهد كبير!
Deep Learning (النقلة النوعية بالـ 2010s): هون الموديل صار
"يعتمد على حاله". إنت بس بتعطيه الصورة خام (Input)
، وهو بشبك طبقات
عصبية معمارية عشان يستخرج الميزات لحاله ويصنفها بتخبطة وحدة
(Feature
Extraction + Classification).

مراحل تطور الـ Deep Learning 📈⏳
عشان نوصل للـ Foundation Models اللي بنشوفها اليوم، الـ AI مر بـ 3 مراحل أساسية:
1. الـ Specialized DL (قبل 2018): كنا نبني معمارية كاملة لمهمة
معينة، وندربها على داتا محدودة (Limited data). يعني موديل لحساب
الأعمار ما بفهم إشي ثاني.
2. الـ Transfer DL (بين 2018 و 2021): بلشنا نفكر بـ "إعادة
التدوير". ندرب موديل على كمية كبيرة من الداتا، بعدين نوخذ
"خبرته" (الميزات اللي تعلمها) ونبني فوقها موديل صغير لمهمتنا الخاصة.
3. الـ Foundation Models (بعد 2021): الخلطة السحرية 🪄! بندرب
موديل واحد عملاق على كميات فلكية (Astronomical) من الداتا. هذا
الموديل صار لحاله جاهز يجاوبك على أي شي بس من خلال توجيه أمر (Prompt)!
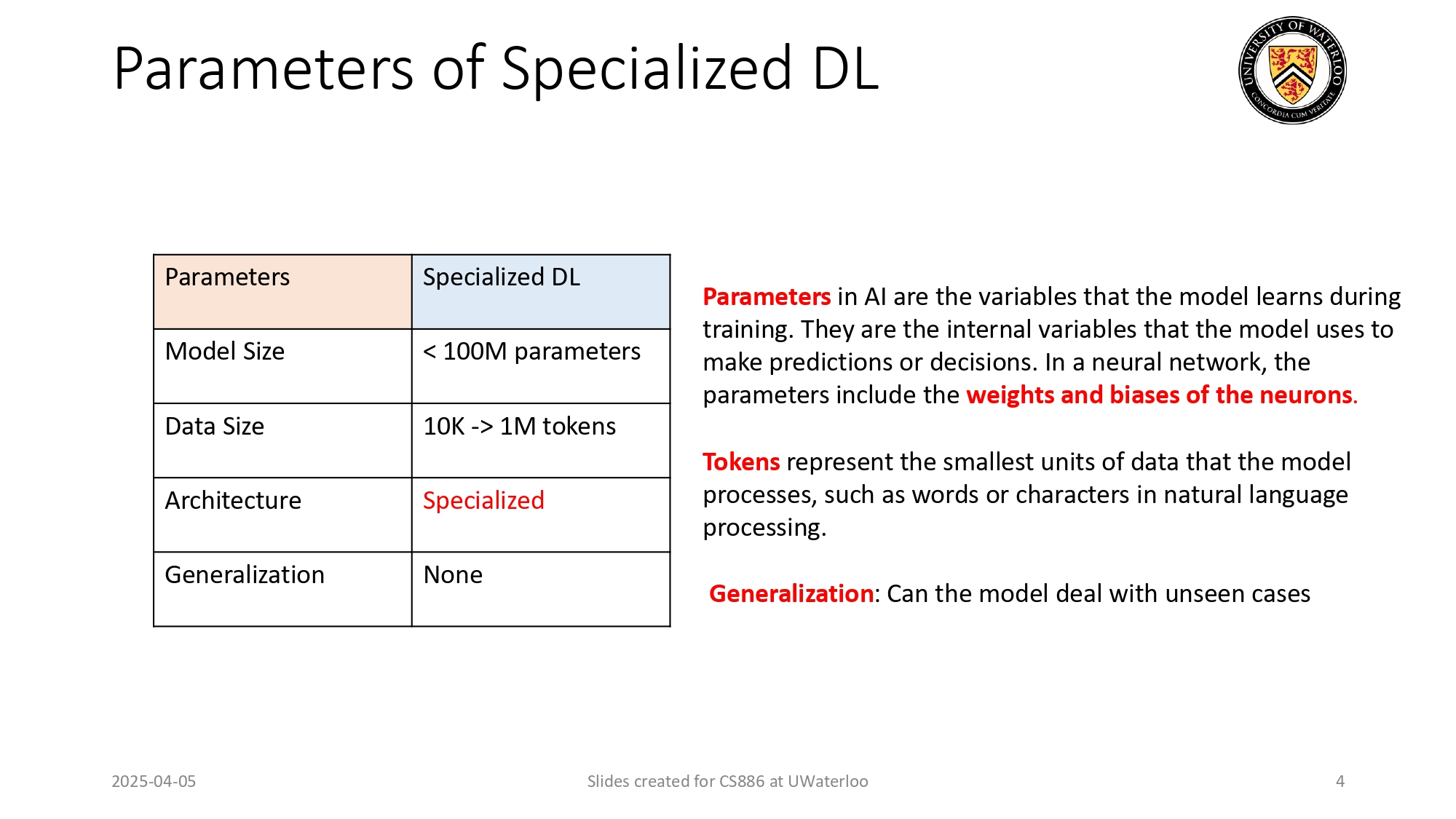
تشريح الموديلات المتخصصة (Specialized DL) 🔬
خلينا نفتح الـ Specialized Models ونشوف شو المواصفات التقنية تبعتها
(بالزمنات):
1. المتغيرات (Parameters): هي المتغيرات الداخلية اللي الموديل
بتعلمها (زي الأوزان والانحيازات - Weights and Biases). بهذيك
الفترة كان حجمها أقل من 100 مليون متغير (يعتبر رقم صغير
عالمياً).
2. حجم الداتا (Data Size): كنا ندربها على داتا حجمها بين 10K لـ 1M Tokens. بس شو هو الـ Token؟ هو أصغر وحدة داتا بعالجها
الموديل (مثلاً حرف، أو كلمة بالـ NLP).
3. المعمارية والتعميم (Architecture & Generalization):
المعمارية كانت مخصصة جداً (Specialized)، والنتيجة؟ الموديل
"غبي" برا مجاله، وما بقدر يعمل Generalization لحالات جديدة أبداً!

إيجابيات وسلبيات الموديلات المتخصصة ⚖️
مع إننا تركناها، بس الـ Specialized DL إلها ميزات وعيوب لازم نعرفها:
الميزات (Pros):
- بتقدر تدربها بكفاءة حتى لو الداتا عندك قليلة (Limited data).
- حجمها صغير ولطيف، يعني سهل جداً تشغلها وترفعها على سيرفرات وتطبيقات الموبايل.
العيوب (Cons):
- كل مهمة بدها "عبقري" يصمملها معمارية خاصة فيها!
- كل موديل بده تعب خرافي في وضع الداتا (Annotating specialized dataset).
- صفر استفادة! الموديل ببدأ يتعلم من الصفر، وما بستفيد من تعب وميزات الموديلات الثانية.
- إذا عندك 10 مهام، بدك ترفع وتدفع تكاليف 10 موديلات على السيرفر، وهذا الإشي مكلف جداً 💸.

نقل المعرفة (Transfer Learning) 🔄🧠
هاي كانت فكرة عبقرية للهروب من فخ "التعلم من الصفر" في الموديلات المتخصصة!
كيف بتشتغل؟
بكل بساطة: بندرب موديل على كمية ضخمة جداً من الداتا (Massive Data) عشان يتعلم "الأساسيات" ويمثلها بشكل برمجي (Neural representation) ويحدد أوزان الموديل.
بكل بساطة: بندرب موديل على كمية ضخمة جداً من الداتا (Massive Data) عشان يتعلم "الأساسيات" ويمثلها بشكل برمجي (Neural representation) ويحدد أوزان الموديل.
شو الفايدة؟
بدل ما الموديل الثاني (تبع مهمتنا الخاصة) يبلش يتعلم وهو أعمى، بنوخذ الأوزان والأساسيات اللي تعلمها الموديل الأول، وبنضيف عليها طبقات (Layers) جديدة بتخص مهمتنا.
بدل ما الموديل الثاني (تبع مهمتنا الخاصة) يبلش يتعلم وهو أعمى، بنوخذ الأوزان والأساسيات اللي تعلمها الموديل الأول، وبنضيف عليها طبقات (Layers) جديدة بتخص مهمتنا.
ليش اشتغلت هاي الفكرة؟
لأنه في الإشي اسمه Cross-task similarity (تشابه بين المهام). يعني اللي تعلم يتعرف على خطوط وحواف الصور، بقدر يستخدم نفس هاي الخبرة عشان يميز صورة سيارة أو شجرة!
لأنه في الإشي اسمه Cross-task similarity (تشابه بين المهام). يعني اللي تعلم يتعرف على خطوط وحواف الصور، بقدر يستخدم نفس هاي الخبرة عشان يميز صورة سيارة أو شجرة!
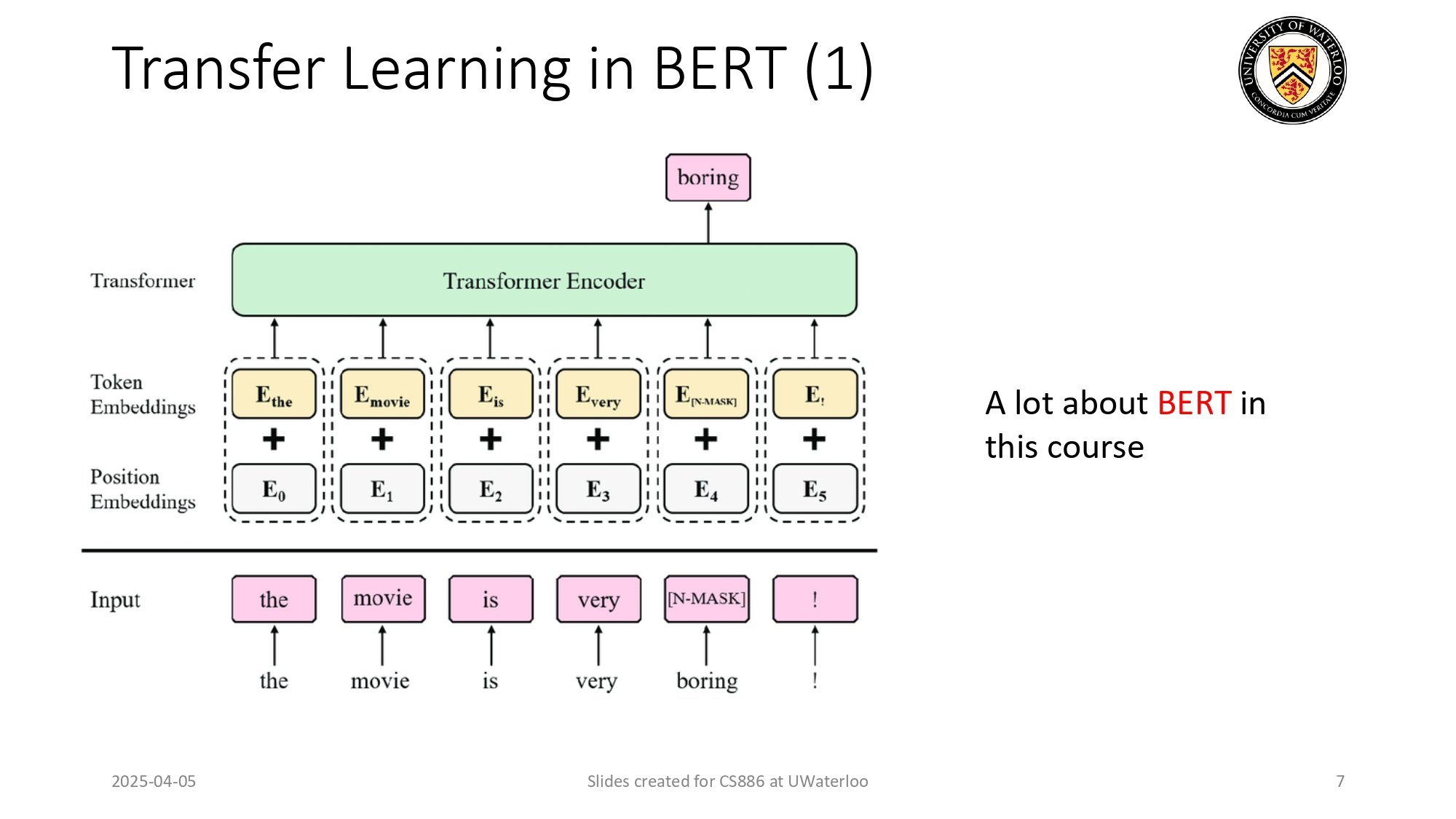
مثال على نقل المعرفة: الموديل الأسطوري BERT 📝
موديل BERT من جوجل هو أشهر مثال على هاي المرحلة بالتعامل مع النصوص
(NLP).
كيف تعلم؟
طريقة تدريبه كانت تشبه لعبة "املأ الفراغ". كنا نعطيه جملة ونخفي منها كلمة (زي: "The movie is very [MASK]")، وهو لازم يحزر الشق الناقص بناءً على سياق الكلمات اللي حواليه.
طريقة تدريبه كانت تشبه لعبة "املأ الفراغ". كنا نعطيه جملة ونخفي منها كلمة (زي: "The movie is very [MASK]")، وهو لازم يحزر الشق الناقص بناءً على سياق الكلمات اللي حواليه.
بهاي الطريقة البسيطة، BERT قدر يتعلم قواعد اللغة الإنجليزية، ومعاني الكلمات، والروابط بينهم من
غير ما نبرمج إشي يدوياً.
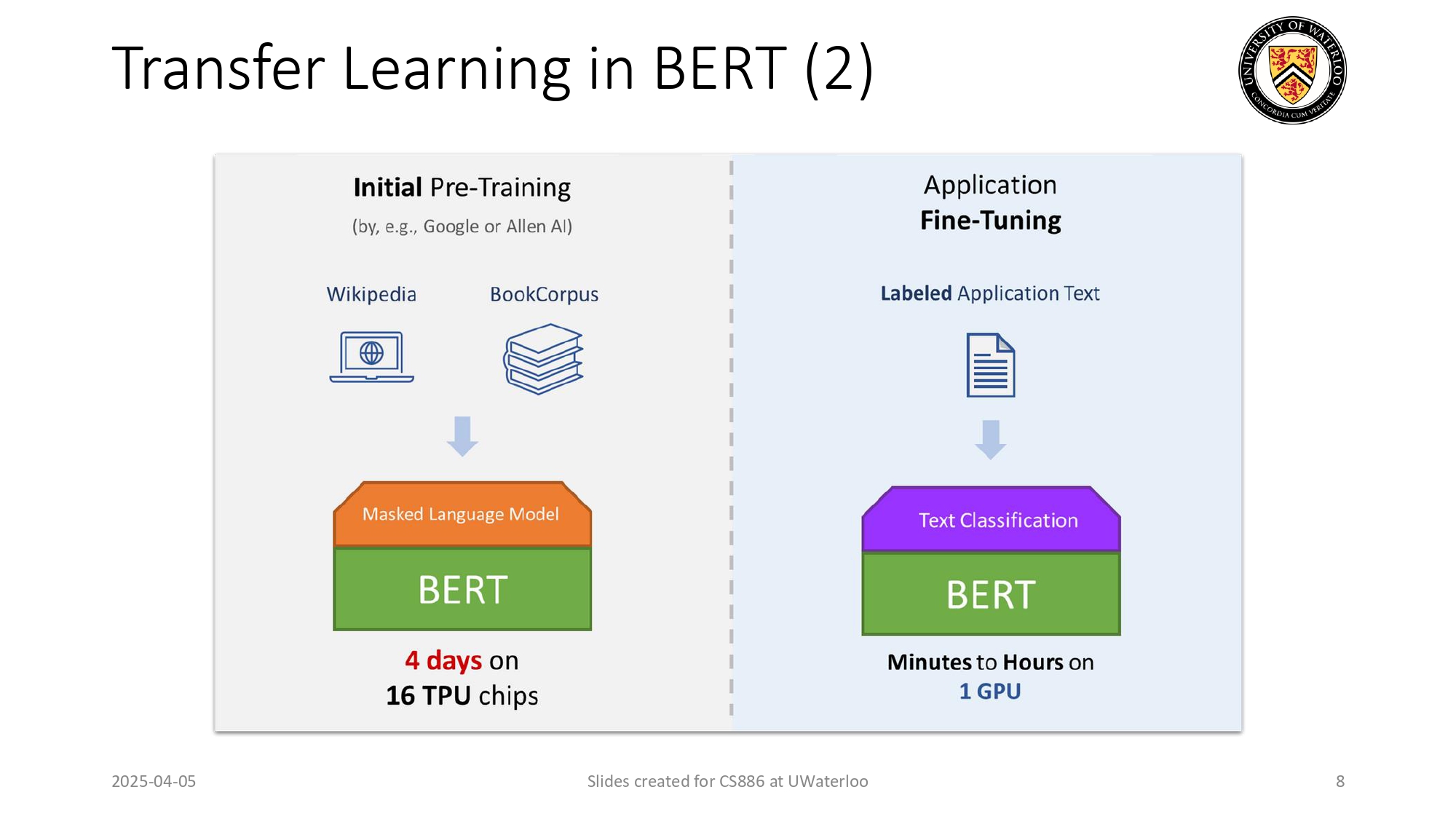
كيف وفّر علينا BERT وقت ومصاري؟ 💸⏱️
خلينا نقارن بين مرحلة التدريب الأساسي ومرحلة التعديل (Fine-Tuning) عشان نفهم قوة الـ Transfer
Learning:
التدريب المسبق (Initial Pre-Training):
جوجل جابت كل ويكيبيديا وكتب ضخمة، ودربت BERT عليها. هاي العملية أخذت 4 أيام على 16 حبة TPU (معالجات خارقة تكلفتها مرعبة).
جوجل جابت كل ويكيبيديا وكتب ضخمة، ودربت BERT عليها. هاي العملية أخذت 4 أيام على 16 حبة TPU (معالجات خارقة تكلفتها مرعبة).
مرحلة التعديل الخاصة فينا (Fine-Tuning):
إحنا بناخذ موديل BERT "الجاهز والفهمان"، وبندربه على داتا صغيرة بتخص مشروعنا (مثلاً: تصنيف إيميلات سبام). هاي العملية بتوخذ دقائق لساعات على GPU واحد بس!
إحنا بناخذ موديل BERT "الجاهز والفهمان"، وبندربه على داتا صغيرة بتخص مشروعنا (مثلاً: تصنيف إيميلات سبام). هاي العملية بتوخذ دقائق لساعات على GPU واحد بس!
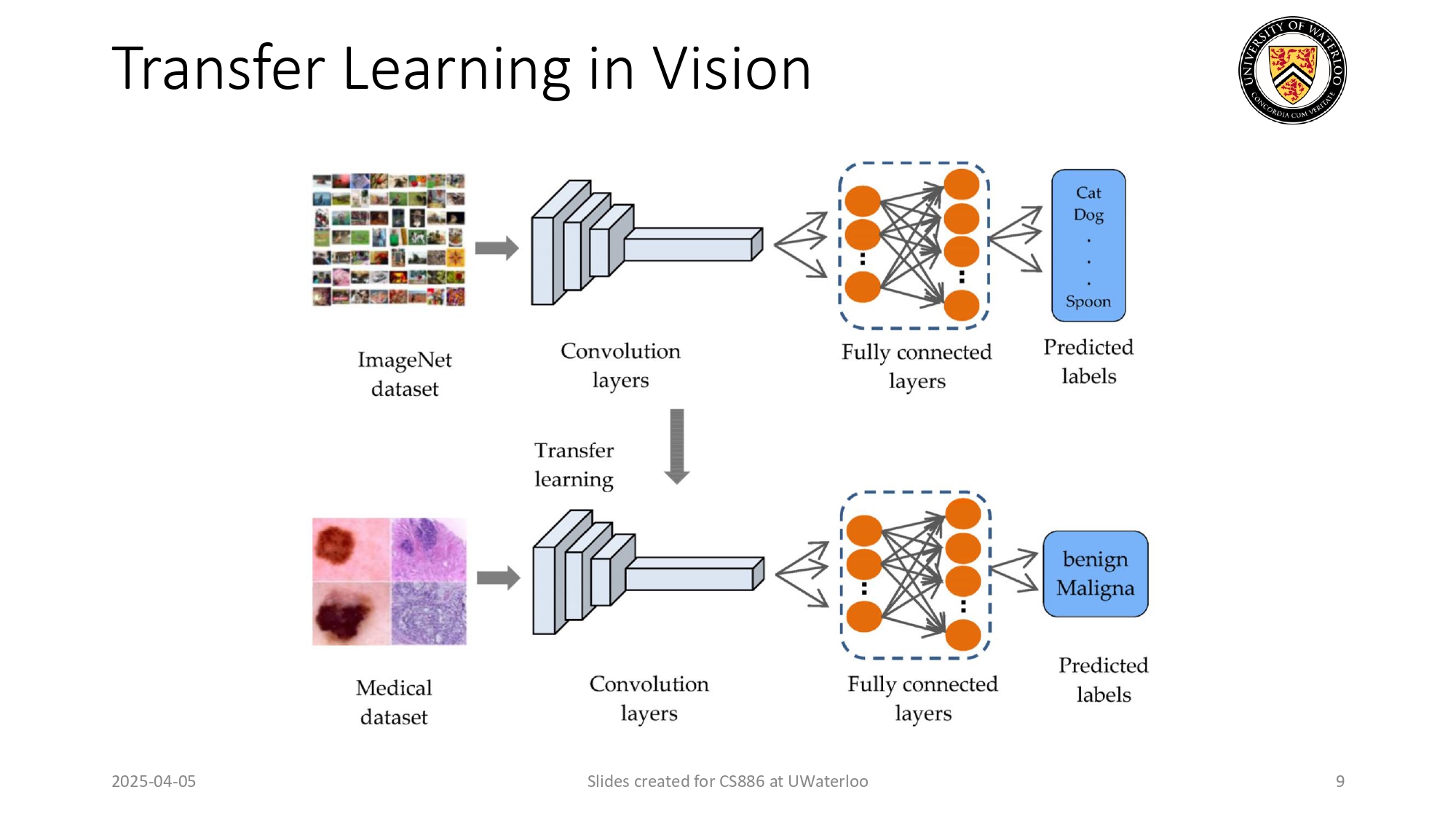
الـ Transfer Learning بالصور (Computer Vision) 🖼️
نفس السحر اللي صار بالنصوص صار بالصور:
الموديل الأصلي: بندرب موديل على داتا ضخمة جداً زي ImageNet (ملايين الصور العشوائية). وظيفة هذا الموديل إنه يتعلم
يستخرج ميزات الصور (زي الحواف والدوائر) من خلال طبقات الفلترة (Convolution Layers).
عملية النقل: لو بدنا موديل يكتشف "السرطان" من صور طبية! بناخذ
طبقات الفلترة (اللي تعلمت تطلع الميزات) زي ما هي من الموديل الأول، وبس بنرمي طبقة النتيجة
النهائية (Fully Connected Layers) وبنبدلها بطبقة جديدة بتعطي
نتيجتين: الطبيعي والخبيث.
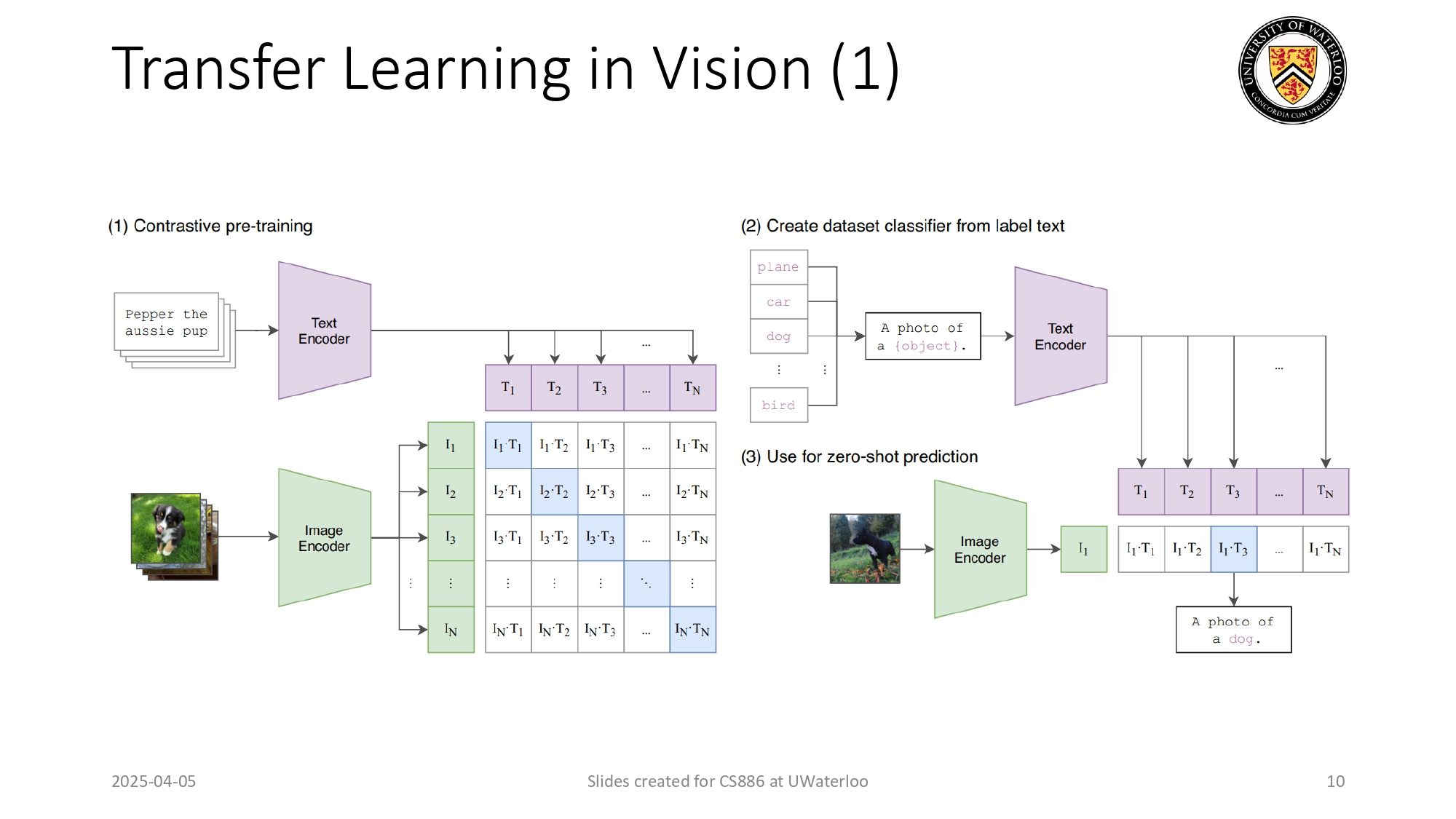
الجيل الجديد للصور: Contrastive Pre-training 📸+📝
هون صرنا ندمج النص والصورة مع بعض (زي موديل CLIP من OpenAI):
كيف بتدرب؟
بنمرر صورة لكلب، وبنفس الوقت بنمرر النص اللي بوصفها. الموديل بحاول يخلي تمثيل الصورة والنص
قريبين من بعض في "فضاء المعاني".
سحر الـ Zero-shot Prediction:
الموديل بيقدر يتعرف على صور عمره ما شافها بس لأنه فاهم "الوصف اللغوي" المرتبط بخصائص الصور.

كيف تغيرت الأرقام؟ (Transfer DL Specs) 📈
خلينا نقارن الجيل القديم بالجيل الثاني (الـ Transfer DL):
حجم الموديل والداتا ضاعف!: المتغيرات (Parameters) قفزت من الملايين لـ 1
مليار. وحجم الداتا صار بالـ مليارات Tokens!
تطور بالمعمارية والـ
Generalization:
بطلنا نشتغل معمارية مفصلة لكل مهمة، صارت معمارية عامة
(General)، وقدرة الموديل على التعميم وحل مهام جديدة صارت منطقية ومقبولة (Reasonable).

إيجابيات وسلبيات الجيل الثاني (Transfer DL) ⚖️
مع كل التطور، لسا في مكان للتحسين (عشان هيك إجت الـ Foundation Models لاحقاً):
الميزات (Pros):
- قدرة خرافية أقوى بكثير من الموديلات المتخصصة القديمة.
- صاحبة فضل وموقف: بتقدر تعمم معرفتها على مهام ما شافتها من قبل.
- ما بتحتاج غير شوية تعديل بسيط جداً (very few fine-tuning) عشان تشتغل ع مهامك.
العيوب (Cons):
- أداؤها ممتاز، بس لسا مش "مثالي" (Not perfect).
- لسا بدها شغل يدوي: بالرغم من ذكائها، لسا مجبورين نعمل Fine-Tuning لكل مهمة جديدة (Downstream tasks). يعني لسا بدك شوية داتا وبدك مهندس صغنون يزبط القصة!
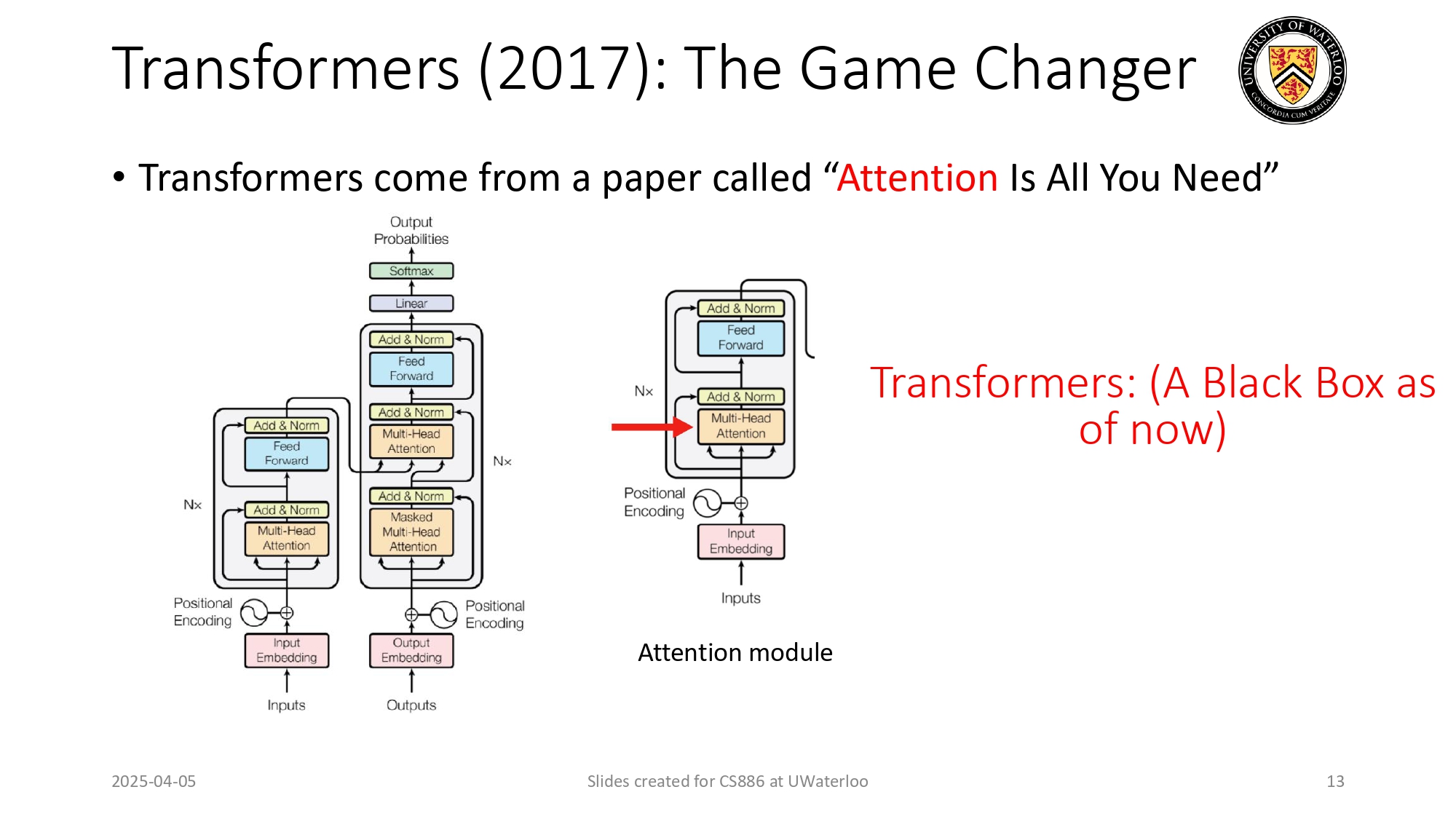
الـ Transformer: اللحظة اللي غيّرت التاريخ ⚡🤖
كل اللي بنشوفه اليوم من ذكاء اصطناعي بدأ فعلياً في 2017 بسبب ورقة بحثية واحدة:
Attention Is All You Need: هاي الورقة قدمت معمارية الـ Transformer. الموديل اللي قدامنا بالرسمة هو الأساس لكل شي، وبكل
بساطة بيتكون من Encoder و Decoder.
ملاحظة: حالياً رح نعتبر هذا الموديل "صندوق أسود" (Black Box) لحد ما نفصص كل قطعة فيه لقدام بالمادة. المهم تعرف إنه هو
المحرك الأساسي!
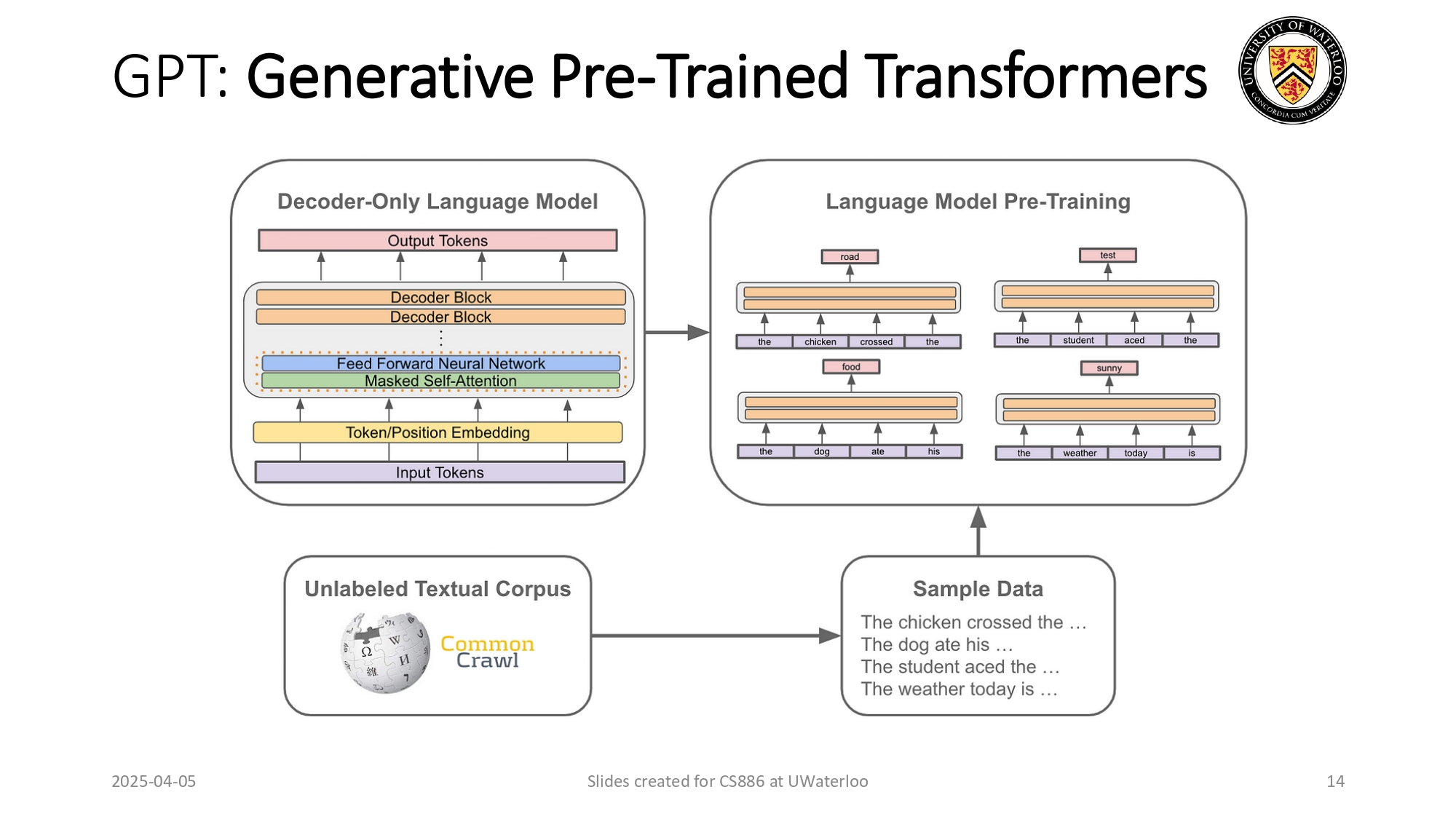
عيلة الـ GPT وكيف بدأت الحكاية 📑🚀
كلمة GPT هي اختصار لـ Generative Pre-trained Transformer، وهون بلشنا
نركز على الـ Decoder-Only.
التدريب غير الموجّه (Unlabeled Training): الموديل اتدرب على
داتا ضخمة جداً من غير ما حدا يحكيله "هاي صح وهاي خطأ" (Unlabeled
Corpus)، مثل أرشفة الإنترنت كاملة (Common Crawl)
وويكيبيديا.
الفكرة كانت بسيطة: "يا موديل، خذ هالداتا وتعلم لحالك كيف الكلمات بتيجي ورا بعضها".

مهمة الـ GPT-2 الوحيدة: توقع الكلمة الجاية! 🔮
في GPT-2، الهدف الأساسي للتدريب (Training Objective) كان واضح ومحدد.
توقع الكلمة التالية (Next Word Prediction): الموديل بيتعامل مع
اللغة كنموذج إحصائي، بيحاول يحسب احتمال ظهور الكلمة الجاية بناءً على كل الكلمات اللي سبقتها.
هاي العملية البسيطة هي اللي بتخلي الـ AI يبدو وكأنه "بفكر"، بس هو فعلياً عبارة عن توقعات إحصائية دقيقة جداً.
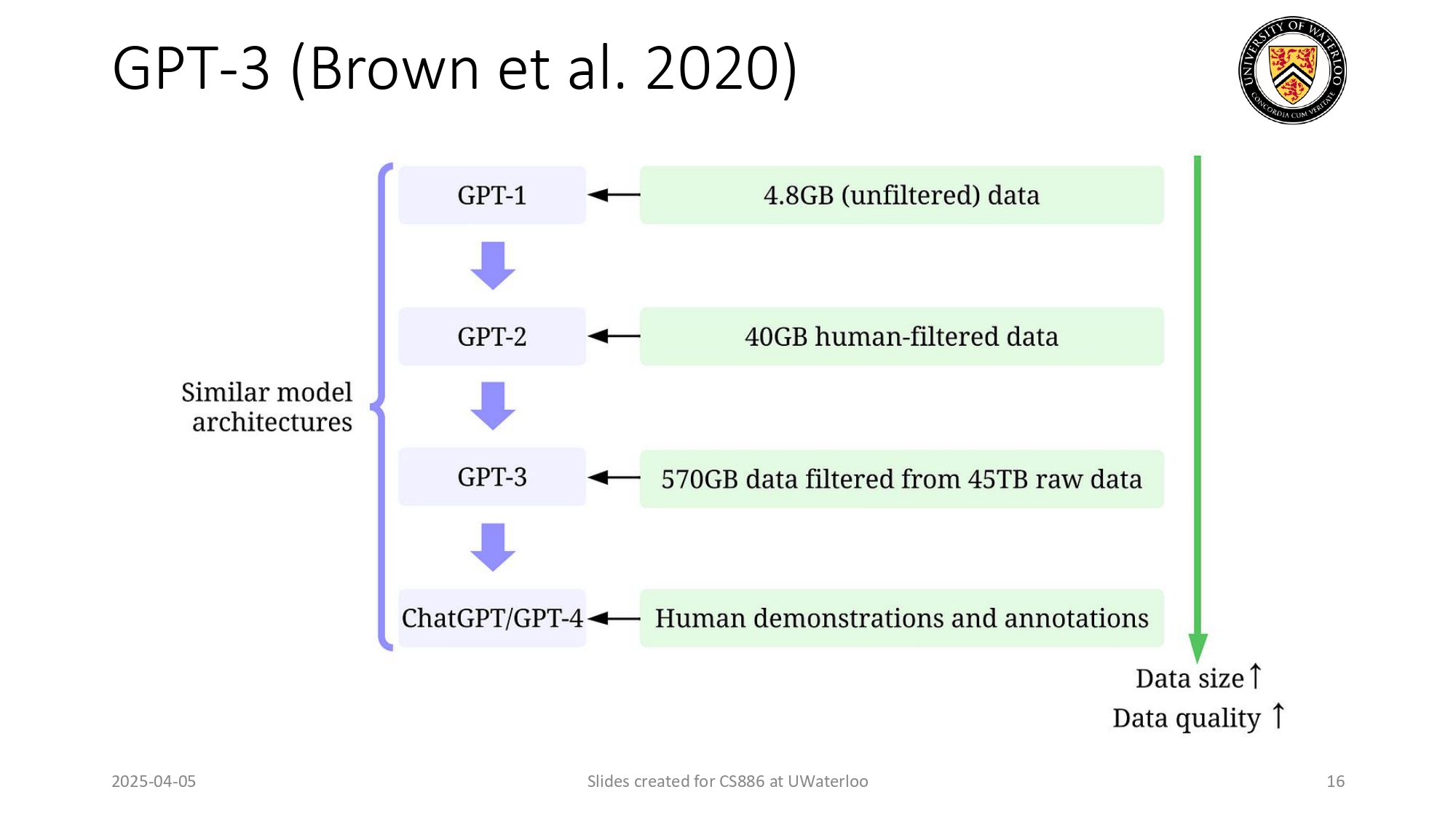
القفزة المرعبة في حجم الداتا! 📉💥
عشان تفهم ليش GPT-3 كان "صدمة" للعالم، شوف الفرق في حجم الداتا اللي اتدرب عليها:
- GPT-1: كان عنده 4.8GB بس.
- GPT-2: ارتفع لـ 40GB داتا مفلترة.
- GPT-3: انفجار داتا! 570GB مفلترة بعناية من أصل 45TB داتا خام.
- GPT-4: صرنا نحكي عن تدخل بشري مباشر (Human demonstrations).
النتيجة واضحة: Data size ↑ & Data
quality ↑ = Super Intelligent
Model!

التعلم من السياق (In-context Learning) 🧠💡
هاض هو السر اللي بخلي ChatGPT يفهمك من غير ما تعيد تدريبه. فيه 3 أنواع أساسية:
1. Zero-Shot (ZSL): الموديل بيقدر يحل المهمة من غير ما يشوف ولا
مثال! بس بتعطيه الأمر ("ترجم هاي الجملة") وبترجمها فوراً.
2. One-Shot (OSL): بتعطيه مثال واحد عشان يفهم النمط اللي بدك
إياه، وهو بكمل لحاله.
3. Few-Shot (FSL): بتعطيه شوية
أمثلة (مثلاً 5 أمثلة) وهيك
الموديل بصير دقيق جداً في المهمة المطلوبة.
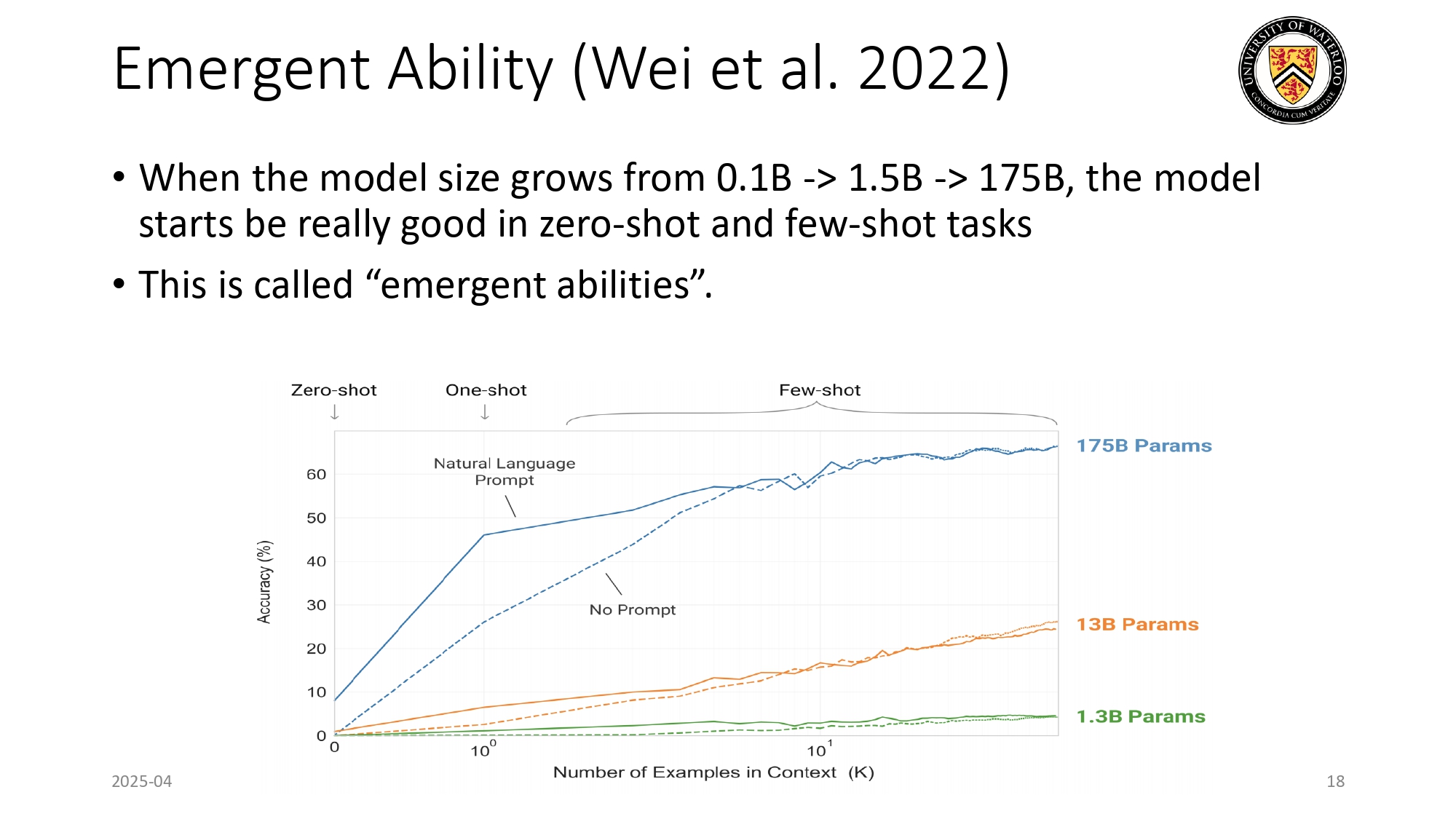
القدرات الناشئة: ليش الحجم بيفرق؟
في علم الـ AI، فيه إشي غريب بصير لما تكبر الموديل لدرجة معينة:
حد الـ 175 مليار: الموديلات
الصغيرة (زي الـ 1.3B) أدائها
في الـ Few-shot بكون ضعيف. بس لما الموديل يوصل لـ 175 مليار
Parameter (زي GPT-3)، دقته بتقفز قفزة مش طبيعية!
هاي بنسميها Emergent abilities. يعني الموديل "فجأة" صار يعرف يحل
مسائل رياضية أو يبرمج بس لأنه صار حجمه عملاق، مع إنه ما اتدرب عليها بشكل خاص! الحجم حرفياً هو
اللي ولّد الذكاء.

خوارزمية الانتشار (unCLIP): كيف بتخلق الصور من العدم؟ 🎨✨
الرسمة اللي بالسلايد بتشرح معمارية الـ unCLIP (المستعملة في DALL-E
2). ركز معي بالخطوات لأنها هي "مربط الفرس":
1. تحويل النص لتمثيل (Frozen Text Encoder):
أول شي النص اللي بتكتبه بيتحول لأرقام (Text Embedding) عن طريق
موديل CLIP متجمد (ما بتغير تدريبه).
2. محرك التوقع (Prior):
هاض الجزء "بتوقع" كيف لازم يكون تمثيل الصورة (Image Embedding)
اللي بطابق نصك. هاض هو العقل المفكر اللي بربط الكلام بالخيال البصري.
3. فك التشفير (Diffusion
Decoder):
هون ببلش السحر! الموديل ببدأ بصورة كلها تشويش (Noise) وبستعمل
الـ Image Embedding كدليل أو "خريطة" عشان يشيل التشويش خطوة
بخطوة لحد ما تطلع صورة الكلب اللي لابس "قبعة زرقاء".
4. التدرج (Super-Resolution Steps):
العملية بتمر بمراحل:
- بطلع صورة صغيرة 64x64 (خام).
- بفوت ع موديل ثانية بكبرها لـ 256x256.
- وبعدين لموديل أخير بخليها بجودة سينمائية 1024x1024.
زبدة الكلام: الموديل ما "برسم"
رسم، هو "بنظف" تشويش بناءً
على أوامر النص! 🧠
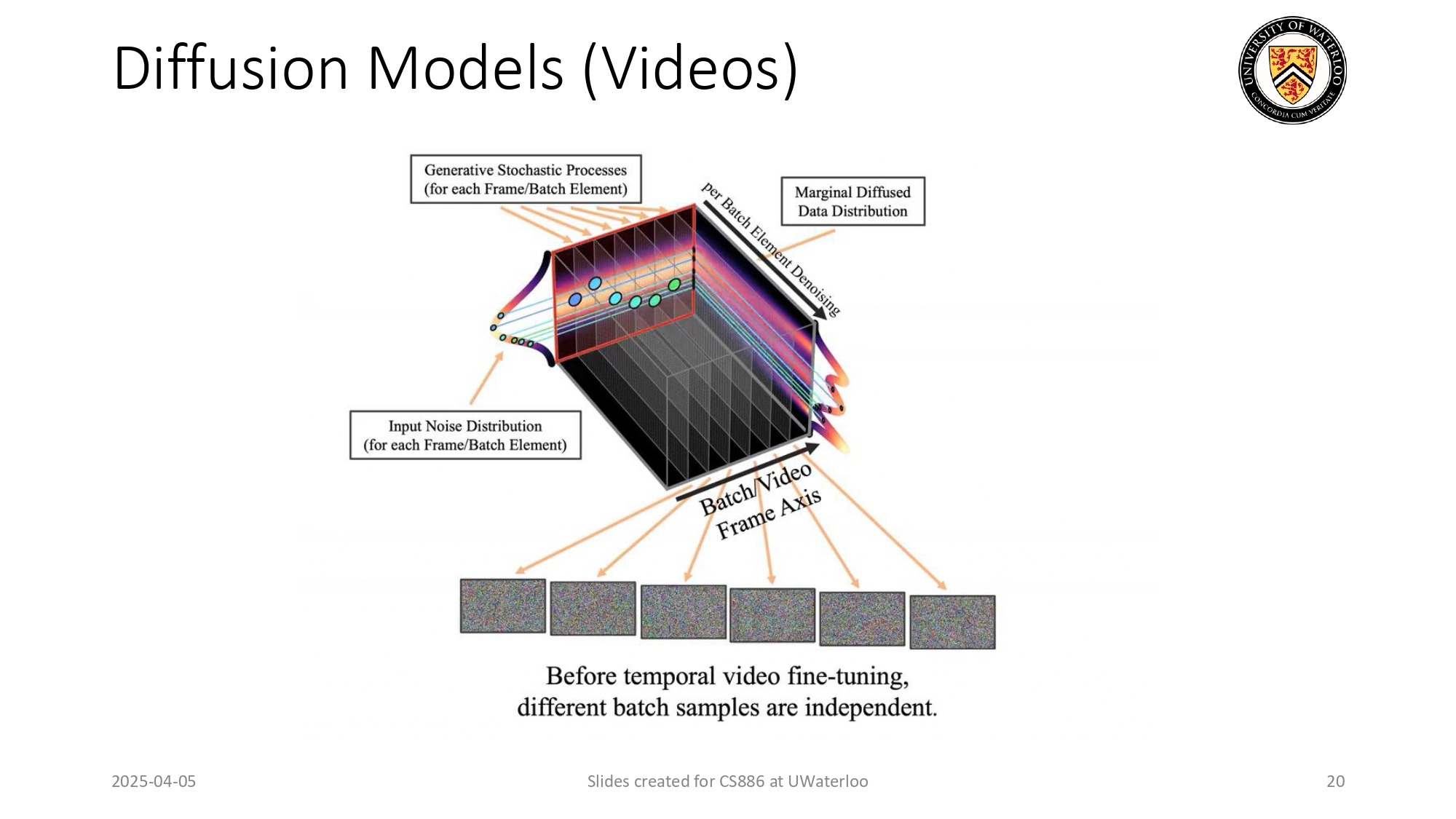
توليد الفيديوهات
توليد الفيديو أصعب بكثير من الصور لأنه فيه بُعد ثالث وهو الزمن
(Temporal
Axis).
كيف بشتغل؟ الموديل بولد مجموعة صور (Frames) مع بعض، ولازم
يتأكد
إنه "التغيير" بين الصورة الأولى والثانية منطقي وسلس عشان ما يطلع الفيديو بقطع أو فيه حركات
غريبة.
هاض اللي بنسميه Temporal fine-tuning، يعني بنعلم الموديل كيف
يربط
الصور ببعض عبر الزمن ليطلع فيديو سينمائي.

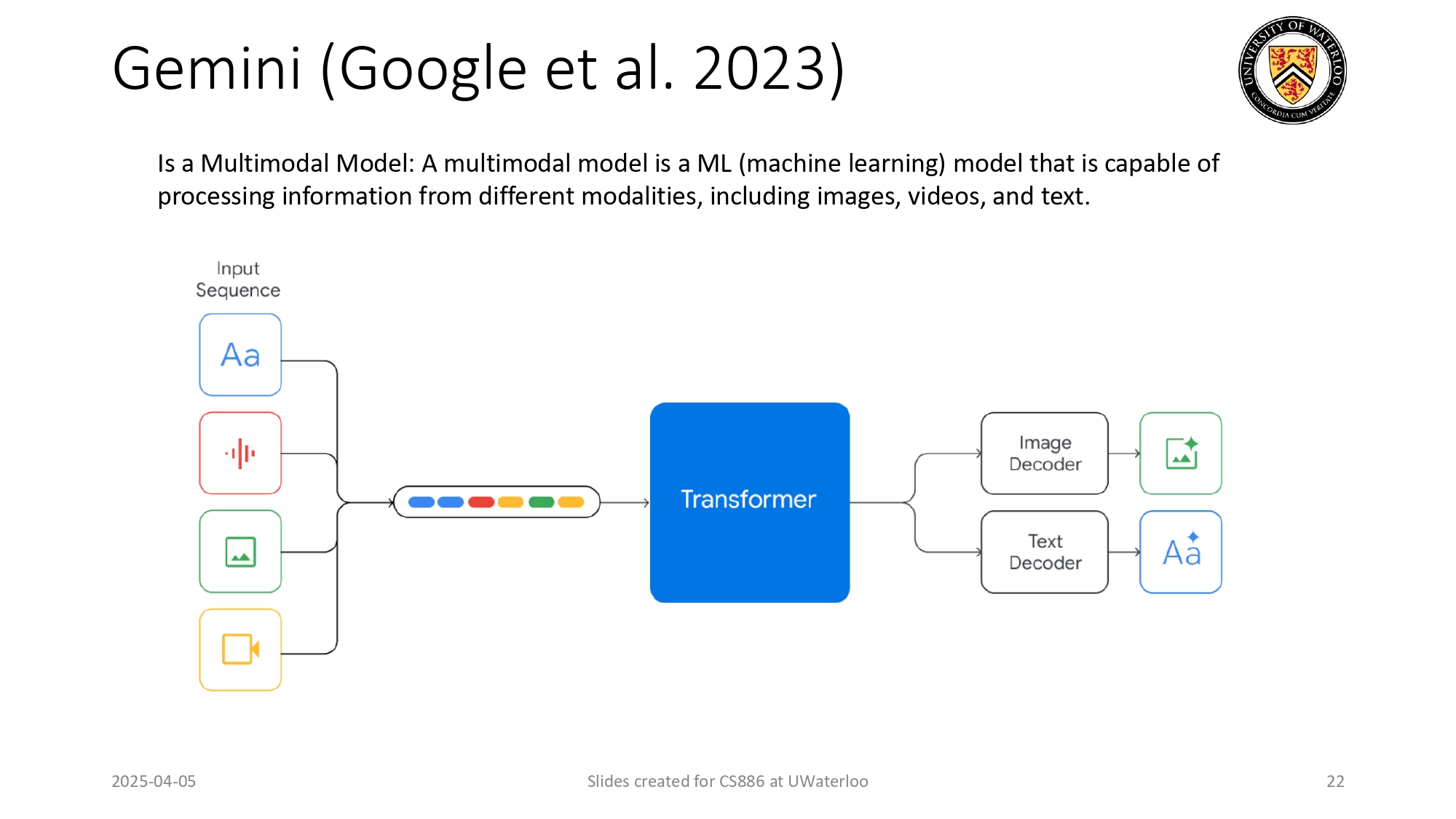
جيميني (Gemini): العملاق الشامل 🌌🤖
ليش Gemini من جوجل كان نقلة نوعية؟ لأنه متعدد الوسائط
(Multimodal).
الموديلات القديمة كانت تتعامل مع نص بس، أو صور بس. لكن Gemini بيقدر يعالج نصوص، أصوات، صور، وفيديو كأنهم لغة واحدة!
زي ما بنشوف بالرسمة، المدخلات (Input Sequence) بتنزت كلها جوا
ترانسفورمر ضخم، وهو بيعرف يفهم العلاقات بينهم ليعطيك النتيجة اللي بدك إياها بأي شكل.
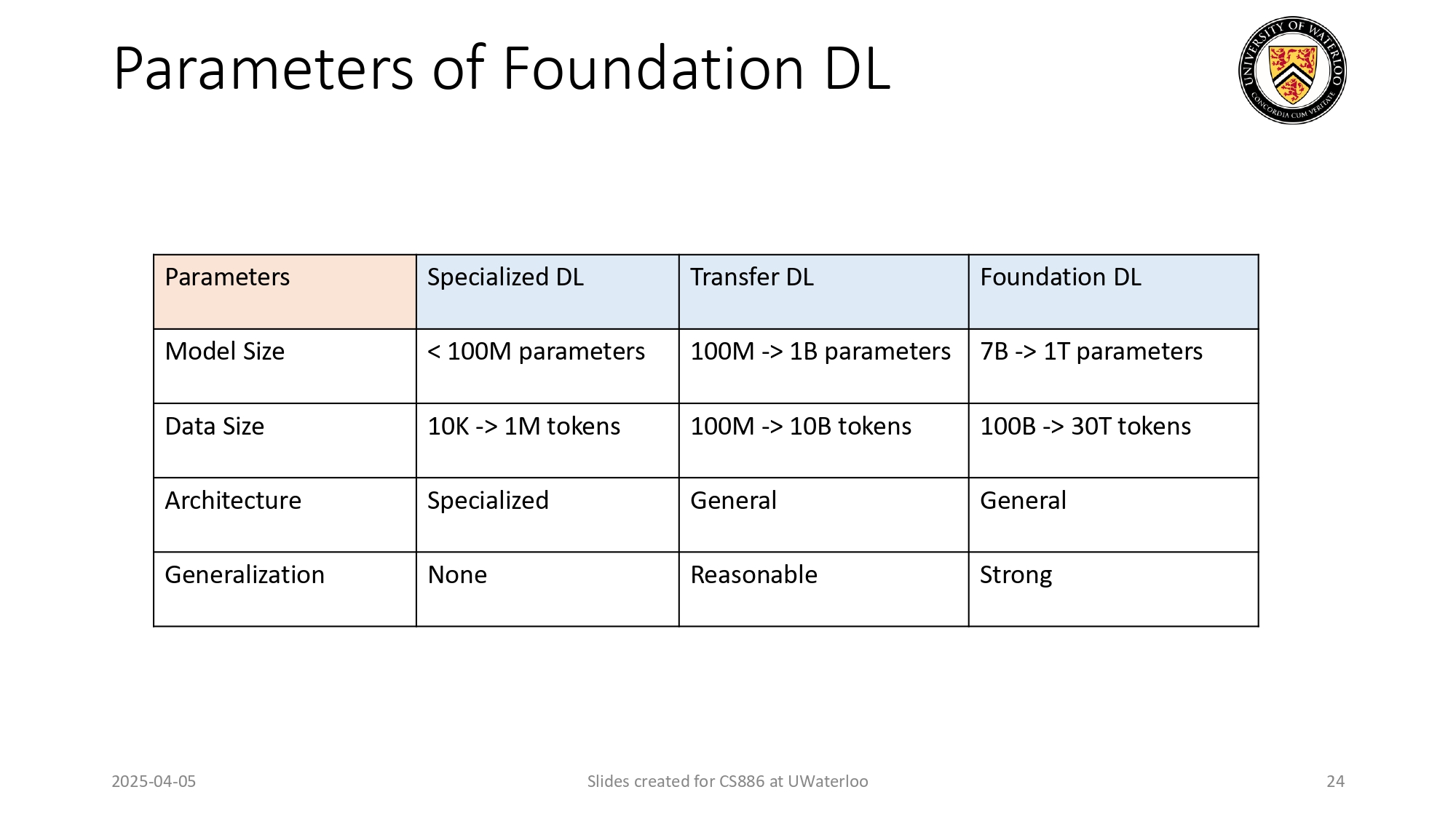
مقارنة العمالقة: من الميجا للتيرا! 📊🐉
وصلنا لآخر مرحلة، خلينا نشوف كيف الـ Foundation DL مسحت الأرض
باللي
قبلها:
1. حجم الموديل: قفزنا من المليار
لـ 1000 مليار (1 Trillion) باراميتر!
2. حجم الداتا: صرنا نحكي عن 30
تريليون Token! (يعني حرفياً أرشفنا كل شي كتبه البشر).
3. النتيجة: قدرة على التعميم
(Generalization) قوية جداً
(Strong) وشاملة لكل أنواع المهام.

سلايدات إضافية (للمطالعة فقط) 📖✅
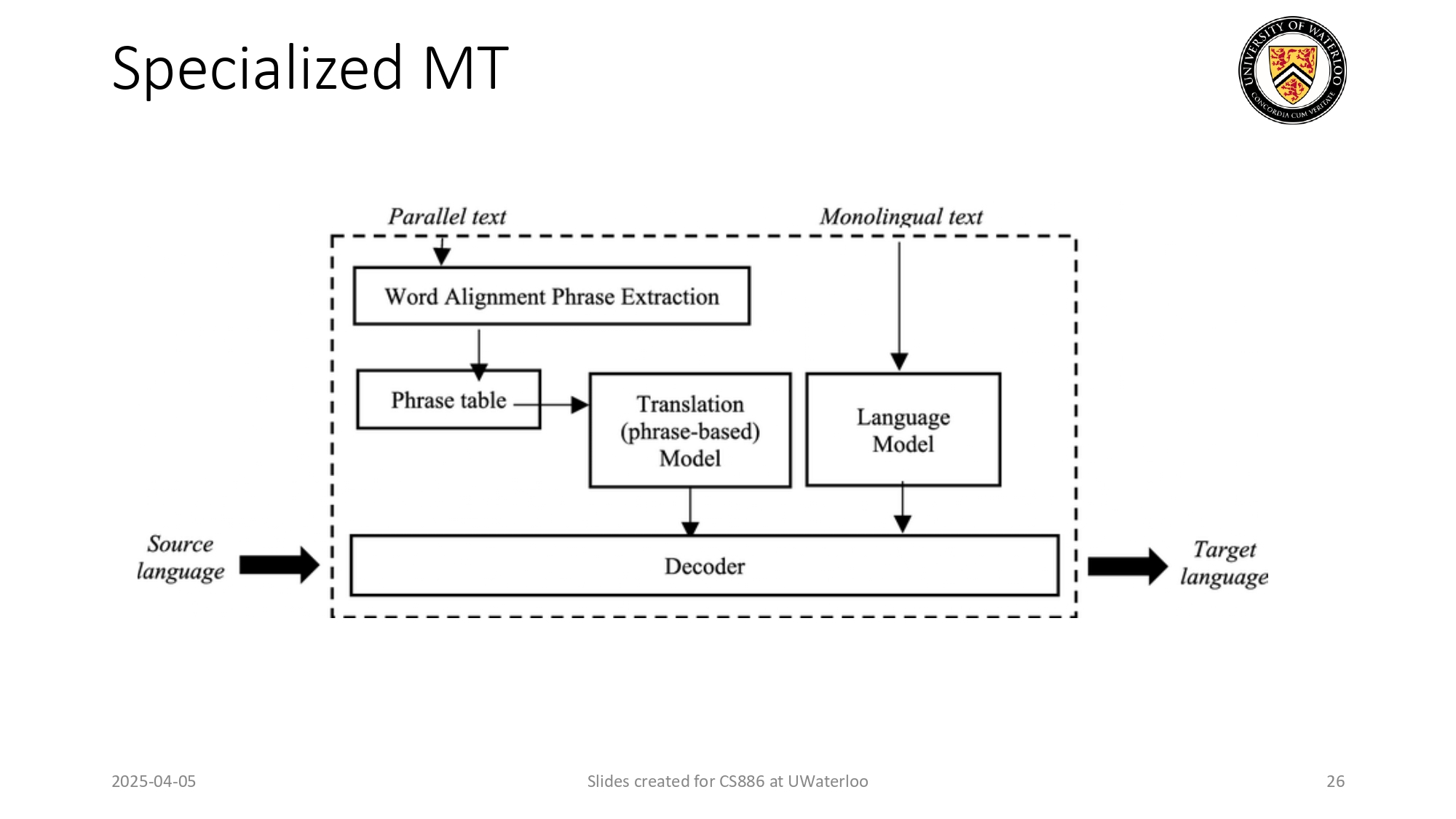
الترجمة الآلية المتخصصة (Specialized MT) 🌍🗣️
مثال على كيف كانت أنظمة الترجمة الآلية تشتغل قبل ثورة الـ Foundation
Models:
الأنظمة كانت معقدة جداً، بتعتمد على قوائم كلمات (Phrase table) وربط يدوي بين الجمل (Word
Alignment). كل لغتين كان بدهم نظام خاص وتدريب وتصميم مختلف تماماً عن غيرهم!
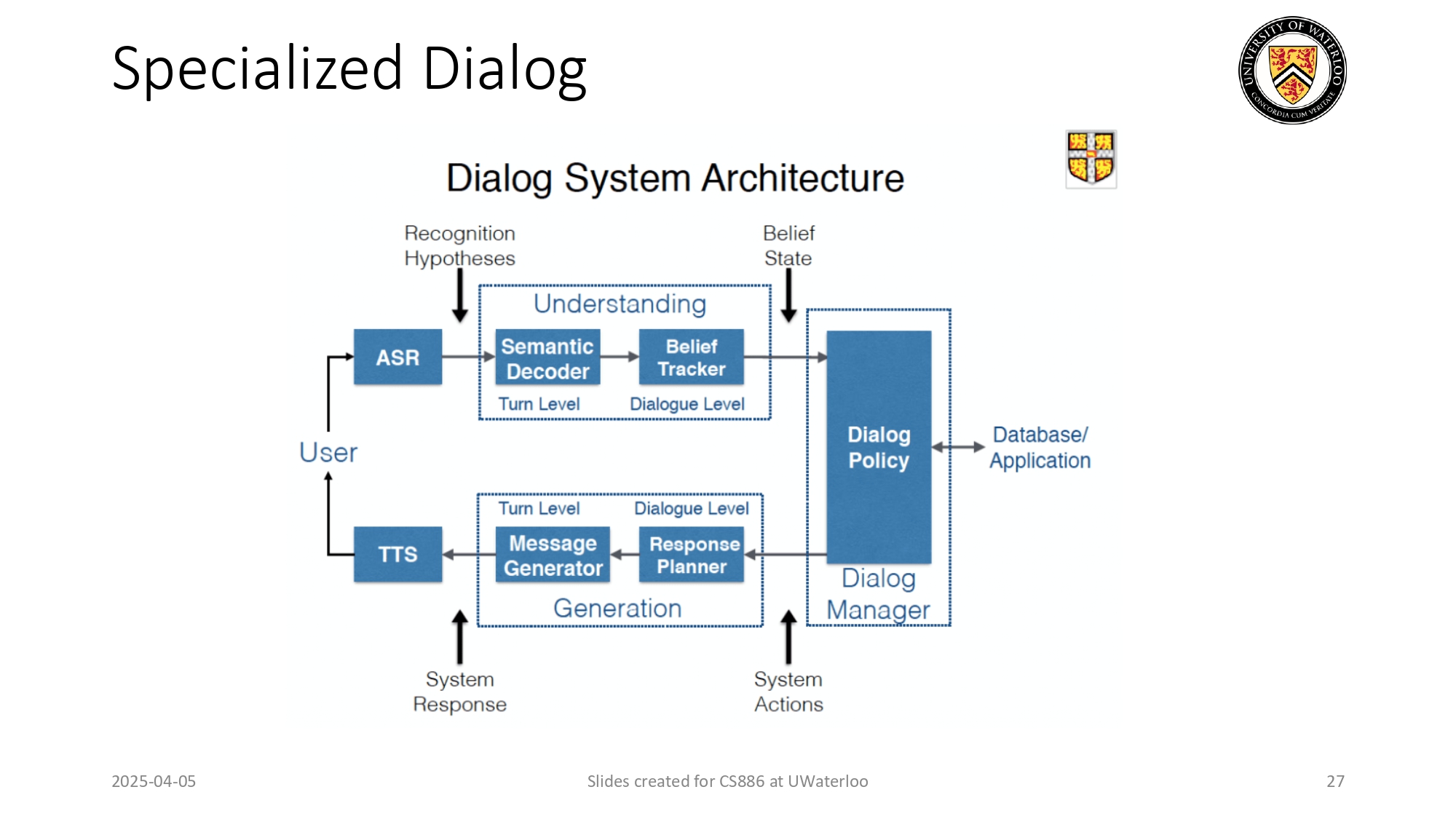
أنظمة الحوار المتخصصة (Specialized Dialog) 💬🤖
الرسمة بتوضح معمارية الـ Dialog Systems القديمة:
كان النظام مقسم لعدة "صناديق" منفصلة: صندوق لتحويل الصوت (ASR)،
وصندوق لفهم المعنى (Semantic Decoder)، وصندوق لإدارة الحوار (Dialog Policy). أي فشل في أي صندوق كان بخلي النظام كامل ينهار!
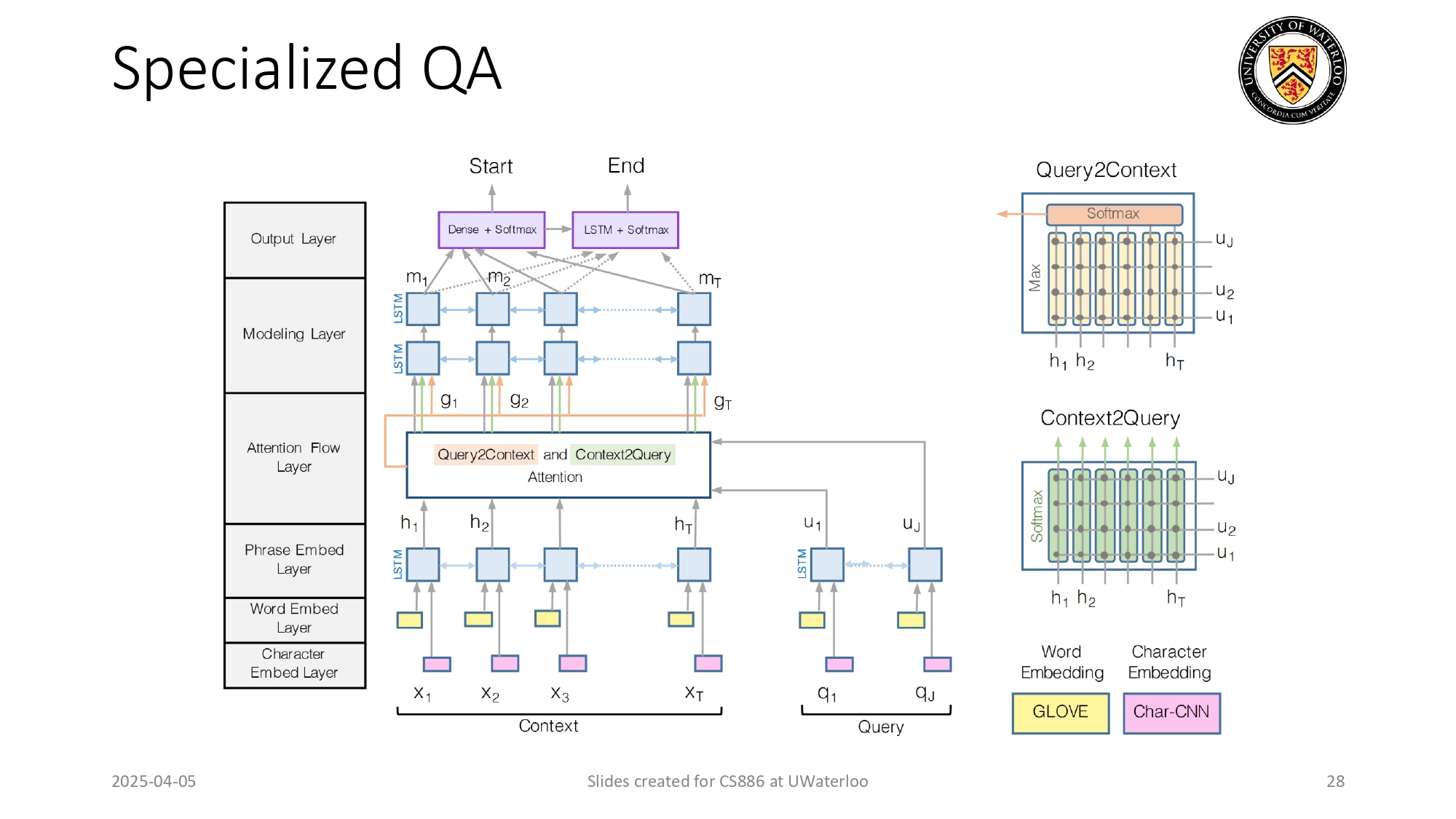
أنظمة الإجابة عن الأسئلة المتخصصة (Specialized QA) 🔍📝
آخر مثال هو الـ Question Answering المتخصص:
شوفو كمية الطبقات (Embedding, Attention, Modeling) عشان بس يقدر
الموديل يقرأ نص ويلاقي "بداية ونهاية" الإجابة. هاي الموديلات كانت عبقرية في مكانها، بس "غبية"
جداً لو سألتها سؤال خارج النص المكتوب قدامها.